Analysis of multi-section ST data¶
This tutorial will guide you through the process of running SpaHDmap on multi-section ST data.
This example uses a 10X Visium dataset of sonic hedgehog (SHH) medulloblastoma from patient-derived orthotopic xenograft (PDOX) mouse models dataset, which has two Palbociclib-treated samples and two untreated control samples. These datasets could be downloaded from Google drive.
SpaHDmap is designed to work with both single-section and multi-section data. The main difference is that in the multi-section case, you need to provide the path for each section, and the reference parameter is used to specify the query-reference pairs for batch effect removal.
1. Import necessary libraries¶
[2]:
import torch
import numpy as np
import SpaHDmap as hdmap
/home/qk/anaconda3/lib/python3.11/importlib/__init__.py:126: FutureWarning: The legacy Dask DataFrame implementation is deprecated and will be removed in a future version. Set the configuration option `dataframe.query-planning` to `True` or None to enable the new Dask Dataframe implementation and silence this warning.
return _bootstrap._gcd_import(name[level:], package, level)
2. Set the parameters and paths¶
In this section, we will set the parameters and paths for the SpaHDmap model, including:
Parameters:
rank: the rank / number of components of the NMF modelseed: the random seedverbose: whether to print the log information
Paths:
root_path: the root path of the experimentproject: the name of the projectresults_path: the path to save the results
Parameters settings¶
By default, we set the rank to 20, the seed to 123, and the verbose to True. You can modify the parameters according to your data.
[3]:
rank = 20
seed = 123
verbose = True
np.random.seed(seed)
torch.manual_seed(seed)
[3]:
<torch._C.Generator at 0x7f497efb70f0>
Paths settings¶
These paths are set with respect to the current directory. You can modify the paths according to your data.
[4]:
root_path = '../experiments/'
project = 'multi_sections'
results_path = f'{root_path}/{project}/Results_Rank{rank}/'
3. Load the data and pre-process¶
The data used in this tutorial is from the Medulloblastoma dataset, which contains 4 sections, could be downloaded from Google Driver.
[5]:
Palbocilib_A = {
"name": "Palbocilib_A",
"image_path": "data/Palbocilib_A/Palbocilib_A.tif",
"spot_coord_path": "data/Palbocilib_A/Palbocilib_A_spot_coord.csv",
"spot_exp_path": "data/Palbocilib_A/Palbocilib_A_expression_nor_top5541SVGs.csv"
}
Palbocilib_B = {
"name": "Palbocilib_B",
"image_path": "data/Palbocilib_B/Palbocilib_B.tif",
"spot_coord_path": "data/Palbocilib_B/Palbocilib_B_spot_coord.csv",
"spot_exp_path": "data/Palbocilib_B/Palbocilib_B_expression_nor_top5541SVGs.csv"
}
Control_C = {
"name": "Control_C",
"image_path": "data/Control_C/Control_C.tif",
"spot_coord_path": "data/Control_C/Control_C_spot_coord.csv",
"spot_exp_path": "data/Control_C/Control_C_expression_nor_top5541SVGs.csv"
}
Control_D = {
"name": "Control_D",
"image_path": "data/Control_D/Control_D.tif",
"spot_coord_path": "data/Control_D/Control_D_spot_coord.csv",
"spot_exp_path": "data/Control_D/Control_D_expression_nor_top5541SVGs.csv"
}
Different from the case of single-section data, you can choose a reference section for each section to remove the batch effect if necessary.
The reference is a dictionary that contains the Query section as the key and the Reference section as the value.
The query or reference section should be in the section list. No section should be both reference and query.
[6]:
# Set the reference section for Palbocilib_B and Control_D
reference = {
'Palbocilib_B': 'Palbocilib_A',
'Control_D': 'Control_C'
}
Next, we set the scale rate and radius. In current case, all sections have the same scale rate and radius,
You can also provide the scale_rate and radius for each section according to your data.
[7]:
scale_rate = 2
radius = 65
Now, we load the data directly (these data have been preprocessed, including normalization, swapping the coordinates and selecting SVGs)
[8]:
# Load the data
pal_A = hdmap.prepare_stdata(section_name=Palbocilib_A['name'],
image_path=Palbocilib_A['image_path'],
spot_coord_path=Palbocilib_A['spot_coord_path'],
spot_exp_path=Palbocilib_A['spot_exp_path'],
scale_rate=scale_rate,
radius=radius,
swap_coord=False) # Has been swapped in this data
pal_B = hdmap.prepare_stdata(section_name=Palbocilib_B['name'],
image_path=Palbocilib_B['image_path'],
spot_coord_path=Palbocilib_B['spot_coord_path'],
spot_exp_path=Palbocilib_B['spot_exp_path'],
scale_rate=scale_rate,
radius=radius,
swap_coord=False) # Has been swapped in this data
ctrl_C = hdmap.prepare_stdata(section_name=Control_C['name'],
image_path=Control_C['image_path'],
spot_coord_path=Control_C['spot_coord_path'],
spot_exp_path=Control_C['spot_exp_path'],
scale_rate=scale_rate,
radius=radius,
swap_coord=False) # Has been swapped in this data
ctrl_D = hdmap.prepare_stdata(section_name=Control_D['name'],
image_path=Control_D['image_path'],
spot_coord_path=Control_D['spot_coord_path'],
spot_exp_path=Control_D['spot_exp_path'],
scale_rate=scale_rate,
radius=radius,
swap_coord=False) # Has been swapped in this data
*** Reading and preparing data from scratch for section Palbocilib_A ***
/home/qk/projects/DeepFuseNMF/SpaHDmap/data/data_util.py:572: ImplicitModificationWarning: Setting element `.obsm['spatial']` of view, initializing view as actual.
adata.obsm['spatial'] = spot_coord.loc[adata.obs_names].values
Pre-processing gene expression data for 3073 spots and 5541 genes.
/home/qk/projects/DeepFuseNMF/SpaHDmap/data/data_util.py:406: UserWarning: Coordinates are not swapped. Make sure the coordinates are in the correct order.
warnings.warn("Coordinates are not swapped. Make sure the coordinates are in the correct order.")
/home/qk/projects/DeepFuseNMF/SpaHDmap/data/data_util.py:410: UserWarning: Data seems to be already normalized, skipping pre-processing.
warnings.warn("Data seems to be already normalized, skipping pre-processing.")
/home/qk/anaconda3/lib/python3.11/site-packages/scanpy/preprocessing/_highly_variable_genes.py:414: UserWarning: `n_top_genes` > number of normalized dispersions, returning all genes with normalized dispersions.
warnings.warn(msg, UserWarning)
Processing image, seems to be HE image.
*** Reading and preparing data from scratch for section Palbocilib_B ***
/home/qk/projects/DeepFuseNMF/SpaHDmap/data/data_util.py:572: ImplicitModificationWarning: Setting element `.obsm['spatial']` of view, initializing view as actual.
adata.obsm['spatial'] = spot_coord.loc[adata.obs_names].values
Pre-processing gene expression data for 2957 spots and 5541 genes.
/home/qk/projects/DeepFuseNMF/SpaHDmap/data/data_util.py:406: UserWarning: Coordinates are not swapped. Make sure the coordinates are in the correct order.
warnings.warn("Coordinates are not swapped. Make sure the coordinates are in the correct order.")
/home/qk/projects/DeepFuseNMF/SpaHDmap/data/data_util.py:410: UserWarning: Data seems to be already normalized, skipping pre-processing.
warnings.warn("Data seems to be already normalized, skipping pre-processing.")
/home/qk/anaconda3/lib/python3.11/site-packages/scanpy/preprocessing/_highly_variable_genes.py:414: UserWarning: `n_top_genes` > number of normalized dispersions, returning all genes with normalized dispersions.
warnings.warn(msg, UserWarning)
Processing image, seems to be HE image.
*** Reading and preparing data from scratch for section Control_C ***
/home/qk/projects/DeepFuseNMF/SpaHDmap/data/data_util.py:572: ImplicitModificationWarning: Setting element `.obsm['spatial']` of view, initializing view as actual.
adata.obsm['spatial'] = spot_coord.loc[adata.obs_names].values
Pre-processing gene expression data for 4380 spots and 5541 genes.
/home/qk/projects/DeepFuseNMF/SpaHDmap/data/data_util.py:406: UserWarning: Coordinates are not swapped. Make sure the coordinates are in the correct order.
warnings.warn("Coordinates are not swapped. Make sure the coordinates are in the correct order.")
/home/qk/projects/DeepFuseNMF/SpaHDmap/data/data_util.py:410: UserWarning: Data seems to be already normalized, skipping pre-processing.
warnings.warn("Data seems to be already normalized, skipping pre-processing.")
Processing image, seems to be HE image.
*** Reading and preparing data from scratch for section Control_D ***
/home/qk/projects/DeepFuseNMF/SpaHDmap/data/data_util.py:572: ImplicitModificationWarning: Setting element `.obsm['spatial']` of view, initializing view as actual.
adata.obsm['spatial'] = spot_coord.loc[adata.obs_names].values
Pre-processing gene expression data for 4216 spots and 5541 genes.
/home/qk/projects/DeepFuseNMF/SpaHDmap/data/data_util.py:406: UserWarning: Coordinates are not swapped. Make sure the coordinates are in the correct order.
warnings.warn("Coordinates are not swapped. Make sure the coordinates are in the correct order.")
/home/qk/projects/DeepFuseNMF/SpaHDmap/data/data_util.py:410: UserWarning: Data seems to be already normalized, skipping pre-processing.
warnings.warn("Data seems to be already normalized, skipping pre-processing.")
/home/qk/anaconda3/lib/python3.11/site-packages/scanpy/preprocessing/_highly_variable_genes.py:414: UserWarning: `n_top_genes` > number of normalized dispersions, returning all genes with normalized dispersions.
warnings.warn(msg, UserWarning)
Processing image, seems to be HE image.
If you want to select SVGs for your data, you can still use select_svgs to complete the task. The only difference from the single-section situation is that you need to provide a list of sections. Then, select_svgs will first check the overlapping genes and select the SVGs based on the rank of the Moran Index across all sections.
[9]:
# hdmap.select_svgs([pal_A, pal_B, ctrl_C, ctrl_D], n_top_genes=3000)
4. Run SpaHDmap¶
Same to case of analyzing single H&E-image 10X Visium ST data, we initialize the Mapper object and run SpaHDmap.
A small difference is that, in this case, Mapper receives a list of sections in the parameter section. Additionally, the parameter reference is a dictionary that assigns the reference section for each query section, which by default is None and is optional for removing batch effect.
Another difference from the single-section situation is as follows:
NMF is performed jointly on all sections to obtain the NMF score for each section.
For GCN and VD, a graph is created for each section individually.
SpaHDmap is pretrained and trained jointly on all sections to obtain the SpaHDmap score for each section.
[10]:
# Initialize the SpaHDmap runner
mapper = hdmap.Mapper([pal_A, pal_B, ctrl_C, ctrl_D], reference=reference, results_path=results_path, rank=rank, verbose=True)
# Run all steps in one function
mapper.run_SpaHDmap()
*** Preparing the tissue splits and creating pseudo spots... ***
*** Found 5534 common genes across all sections. ***
*** The split size is set to 256 pixels. ***
For section Palbocilib_A, divide the tissue into 618 sub-tissues, and create 15000 pseudo spots.
For section Palbocilib_B, divide the tissue into 647 sub-tissues, and create 15000 pseudo spots.
For section Control_C, divide the tissue into 807 sub-tissues, and create 20000 pseudo spots.
For section Control_D, divide the tissue into 796 sub-tissues, and create 20000 pseudo spots.
*** Using GPU ***
Step 1: Run NMF
*** Performing NMF... ***
*** Visualizing and saving the embeddings of NMF... ***
Step 2: Pre-train the SpaHDmap model
/home/qk/projects/DeepFuseNMF/SpaHDmap/train.py:525: FutureWarning: `torch.cuda.amp.GradScaler(args...)` is deprecated. Please use `torch.amp.GradScaler('cuda', args...)` instead.
self.scaler = torch.cuda.amp.GradScaler()
/home/qk/projects/DeepFuseNMF/SpaHDmap/train.py:571: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with torch.cuda.amp.autocast():
[Iter: 200 / 5000], Epoch: 3, Loss: 0.046121, Learning rate: 3.984269e-04
[Iter: 400 / 5000], Epoch: 5, Loss: 0.007932, Learning rate: 3.937323e-04
[Iter: 600 / 5000], Epoch: 7, Loss: 0.000647, Learning rate: 3.859904e-04
[Iter: 800 / 5000], Epoch: 9, Loss: 0.000397, Learning rate: 3.753232e-04
[Iter: 1000 / 5000], Epoch: 12, Loss: 0.000293, Learning rate: 3.618989e-04
[Iter: 1200 / 5000], Epoch: 14, Loss: 0.000235, Learning rate: 3.459292e-04
[Iter: 1400 / 5000], Epoch: 16, Loss: 0.000197, Learning rate: 3.276661e-04
[Iter: 1600 / 5000], Epoch: 18, Loss: 0.000155, Learning rate: 3.073974e-04
[Iter: 1800 / 5000], Epoch: 20, Loss: 0.000152, Learning rate: 2.854430e-04
[Iter: 2000 / 5000], Epoch: 23, Loss: 0.000122, Learning rate: 2.621489e-04
[Iter: 2200 / 5000], Epoch: 25, Loss: 0.000107, Learning rate: 2.378826e-04
[Iter: 2400 / 5000], Epoch: 27, Loss: 0.000097, Learning rate: 2.130267e-04
[Iter: 2600 / 5000], Epoch: 29, Loss: 0.000089, Learning rate: 1.879733e-04
[Iter: 2800 / 5000], Epoch: 32, Loss: 0.000083, Learning rate: 1.631174e-04
[Iter: 3000 / 5000], Epoch: 34, Loss: 0.000077, Learning rate: 1.388511e-04
[Iter: 3200 / 5000], Epoch: 36, Loss: 0.000070, Learning rate: 1.155570e-04
[Iter: 3400 / 5000], Epoch: 38, Loss: 0.000067, Learning rate: 9.360255e-05
Reached convergence, stop early
*** Finished pre-training the SpaHDmap model and saved at ../experiments//multi_sections/Results_Rank20//models//pretrained_model.pth ***
Step 3: Train the GCN model
*** Performing GCN... ***
*** Training GCN for Palbocilib_A... ***
[Iter: 200 / 5000], Loss: 0.015325, Learning rate: 4.985215e-03
[Iter: 400 / 5000], Loss: 0.006314, Learning rate: 4.941093e-03
[Iter: 600 / 5000], Loss: 0.005907, Learning rate: 4.868331e-03
[Iter: 800 / 5000], Loss: 0.005759, Learning rate: 4.768075e-03
[Iter: 1000 / 5000], Loss: 0.005673, Learning rate: 4.641907e-03
[Iter: 1200 / 5000], Loss: 0.005619, Learning rate: 4.491816e-03
[Iter: 1400 / 5000], Loss: 0.005575, Learning rate: 4.320170e-03
[Iter: 1600 / 5000], Loss: 0.005538, Learning rate: 4.129675e-03
[Iter: 1800 / 5000], Loss: 0.005512, Learning rate: 3.923336e-03
[Iter: 2000 / 5000], Loss: 0.005489, Learning rate: 3.704407e-03
[Iter: 2200 / 5000], Loss: 0.005466, Learning rate: 3.476340e-03
[Iter: 2400 / 5000], Loss: 0.005446, Learning rate: 3.242732e-03
[Iter: 2600 / 5000], Loss: 0.005432, Learning rate: 3.007268e-03
[Iter: 2800 / 5000], Loss: 0.005420, Learning rate: 2.773660e-03
[Iter: 3000 / 5000], Loss: 0.005409, Learning rate: 2.545593e-03
[Iter: 3200 / 5000], Loss: 0.005399, Learning rate: 2.326664e-03
[Iter: 3400 / 5000], Loss: 0.005389, Learning rate: 2.120325e-03
[Iter: 3600 / 5000], Loss: 0.005381, Learning rate: 1.929830e-03
[Iter: 3800 / 5000], Loss: 0.005374, Learning rate: 1.758184e-03
[Iter: 4000 / 5000], Loss: 0.005367, Learning rate: 1.608093e-03
[Iter: 4200 / 5000], Loss: 0.005361, Learning rate: 1.481925e-03
[Iter: 4400 / 5000], Loss: 0.005357, Learning rate: 1.381669e-03
[Iter: 4600 / 5000], Loss: 0.005353, Learning rate: 1.308907e-03
[Iter: 4800 / 5000], Loss: 0.005349, Learning rate: 1.264785e-03
[Iter: 5000 / 5000], Loss: 0.005346, Learning rate: 1.250000e-03
*** Training GCN for Palbocilib_B... ***
[Iter: 200 / 5000], Loss: 0.016280, Learning rate: 4.985215e-03
[Iter: 400 / 5000], Loss: 0.006049, Learning rate: 4.941093e-03
[Iter: 600 / 5000], Loss: 0.005465, Learning rate: 4.868331e-03
[Iter: 800 / 5000], Loss: 0.005299, Learning rate: 4.768075e-03
[Iter: 1000 / 5000], Loss: 0.005217, Learning rate: 4.641907e-03
[Iter: 1200 / 5000], Loss: 0.005161, Learning rate: 4.491816e-03
[Iter: 1400 / 5000], Loss: 0.005114, Learning rate: 4.320170e-03
[Iter: 1600 / 5000], Loss: 0.005079, Learning rate: 4.129675e-03
[Iter: 1800 / 5000], Loss: 0.005049, Learning rate: 3.923336e-03
[Iter: 2000 / 5000], Loss: 0.005026, Learning rate: 3.704407e-03
[Iter: 2200 / 5000], Loss: 0.005006, Learning rate: 3.476340e-03
[Iter: 2400 / 5000], Loss: 0.004990, Learning rate: 3.242732e-03
[Iter: 2600 / 5000], Loss: 0.004975, Learning rate: 3.007268e-03
[Iter: 2800 / 5000], Loss: 0.004963, Learning rate: 2.773660e-03
[Iter: 3000 / 5000], Loss: 0.004952, Learning rate: 2.545593e-03
[Iter: 3200 / 5000], Loss: 0.004943, Learning rate: 2.326664e-03
[Iter: 3400 / 5000], Loss: 0.004934, Learning rate: 2.120325e-03
[Iter: 3600 / 5000], Loss: 0.004927, Learning rate: 1.929830e-03
[Iter: 3800 / 5000], Loss: 0.004919, Learning rate: 1.758184e-03
[Iter: 4000 / 5000], Loss: 0.004913, Learning rate: 1.608093e-03
[Iter: 4200 / 5000], Loss: 0.004906, Learning rate: 1.481925e-03
[Iter: 4400 / 5000], Loss: 0.004901, Learning rate: 1.381669e-03
[Iter: 4600 / 5000], Loss: 0.004895, Learning rate: 1.308907e-03
[Iter: 4800 / 5000], Loss: 0.004890, Learning rate: 1.264785e-03
[Iter: 5000 / 5000], Loss: 0.004885, Learning rate: 1.250000e-03
*** Training GCN for Control_C... ***
[Iter: 200 / 5000], Loss: 0.018465, Learning rate: 4.985215e-03
[Iter: 400 / 5000], Loss: 0.007924, Learning rate: 4.941093e-03
[Iter: 600 / 5000], Loss: 0.006577, Learning rate: 4.868331e-03
[Iter: 800 / 5000], Loss: 0.006375, Learning rate: 4.768075e-03
[Iter: 1000 / 5000], Loss: 0.006314, Learning rate: 4.641907e-03
[Iter: 1200 / 5000], Loss: 0.006272, Learning rate: 4.491816e-03
[Iter: 1400 / 5000], Loss: 0.006238, Learning rate: 4.320170e-03
[Iter: 1600 / 5000], Loss: 0.006222, Learning rate: 4.129675e-03
[Iter: 1800 / 5000], Loss: 0.006207, Learning rate: 3.923336e-03
[Iter: 2000 / 5000], Loss: 0.006191, Learning rate: 3.704407e-03
[Iter: 2200 / 5000], Loss: 0.006178, Learning rate: 3.476340e-03
[Iter: 2400 / 5000], Loss: 0.006171, Learning rate: 3.242732e-03
[Iter: 2600 / 5000], Loss: 0.006162, Learning rate: 3.007268e-03
[Iter: 2800 / 5000], Loss: 0.006153, Learning rate: 2.773660e-03
[Iter: 3000 / 5000], Loss: 0.006148, Learning rate: 2.545593e-03
[Iter: 3200 / 5000], Loss: 0.006143, Learning rate: 2.326664e-03
[Iter: 3400 / 5000], Loss: 0.006138, Learning rate: 2.120325e-03
[Iter: 3600 / 5000], Loss: 0.006134, Learning rate: 1.929830e-03
[Iter: 3800 / 5000], Loss: 0.006130, Learning rate: 1.758184e-03
[Iter: 4000 / 5000], Loss: 0.006126, Learning rate: 1.608093e-03
[Iter: 4200 / 5000], Loss: 0.006123, Learning rate: 1.481925e-03
[Iter: 4400 / 5000], Loss: 0.006121, Learning rate: 1.381669e-03
[Iter: 4600 / 5000], Loss: 0.006118, Learning rate: 1.308907e-03
[Iter: 4800 / 5000], Loss: 0.006115, Learning rate: 1.264785e-03
[Iter: 5000 / 5000], Loss: 0.006113, Learning rate: 1.250000e-03
*** Training GCN for Control_D... ***
[Iter: 200 / 5000], Loss: 0.015409, Learning rate: 4.985215e-03
[Iter: 400 / 5000], Loss: 0.006287, Learning rate: 4.941093e-03
[Iter: 600 / 5000], Loss: 0.005751, Learning rate: 4.868331e-03
[Iter: 800 / 5000], Loss: 0.005601, Learning rate: 4.768075e-03
[Iter: 1000 / 5000], Loss: 0.005532, Learning rate: 4.641907e-03
[Iter: 1200 / 5000], Loss: 0.005502, Learning rate: 4.491816e-03
[Iter: 1400 / 5000], Loss: 0.005472, Learning rate: 4.320170e-03
[Iter: 1600 / 5000], Loss: 0.005454, Learning rate: 4.129675e-03
[Iter: 1800 / 5000], Loss: 0.005436, Learning rate: 3.923336e-03
[Iter: 2000 / 5000], Loss: 0.005421, Learning rate: 3.704407e-03
[Iter: 2200 / 5000], Loss: 0.005410, Learning rate: 3.476340e-03
[Iter: 2400 / 5000], Loss: 0.005399, Learning rate: 3.242732e-03
[Iter: 2600 / 5000], Loss: 0.005388, Learning rate: 3.007268e-03
[Iter: 2800 / 5000], Loss: 0.005380, Learning rate: 2.773660e-03
[Iter: 3000 / 5000], Loss: 0.005372, Learning rate: 2.545593e-03
[Iter: 3200 / 5000], Loss: 0.005365, Learning rate: 2.326664e-03
[Iter: 3400 / 5000], Loss: 0.005359, Learning rate: 2.120325e-03
[Iter: 3600 / 5000], Loss: 0.005353, Learning rate: 1.929830e-03
[Iter: 3800 / 5000], Loss: 0.005349, Learning rate: 1.758184e-03
[Iter: 4000 / 5000], Loss: 0.005345, Learning rate: 1.608093e-03
[Iter: 4200 / 5000], Loss: 0.005341, Learning rate: 1.481925e-03
[Iter: 4400 / 5000], Loss: 0.005338, Learning rate: 1.381669e-03
[Iter: 4600 / 5000], Loss: 0.005335, Learning rate: 1.308907e-03
[Iter: 4800 / 5000], Loss: 0.005333, Learning rate: 1.264785e-03
[Iter: 5000 / 5000], Loss: 0.005331, Learning rate: 1.250000e-03
*** Visualizing and saving the embeddings of GCN... ***
/home/qk/projects/DeepFuseNMF/SpaHDmap/utils/visualize.py:137: RuntimeWarning: invalid value encountered in divide
tmp_score = score[idx, :, :] if use_score in ['SpaHDmap', 'VD'] else score[idx, :, :] / score[idx, :, :].max()
/home/qk/projects/DeepFuseNMF/SpaHDmap/utils/visualize.py:144: RuntimeWarning: invalid value encountered in cast
resized_score = cv2.resize(filtered_score.astype(np.uint8),
/home/qk/projects/DeepFuseNMF/SpaHDmap/utils/visualize.py:69: RuntimeWarning: invalid value encountered in cast
cv2.imwrite(full_path, image_data.astype(np.uint8))
Step 4: Run Voronoi Diagram
/home/qk/projects/DeepFuseNMF/SpaHDmap/train.py:933: RuntimeWarning: Mean of empty slice.
mean_score_input = smooth_input[nonzero_index_input[0], nonzero_index_input[1]].mean()
/home/qk/anaconda3/lib/python3.11/site-packages/numpy/core/_methods.py:129: RuntimeWarning: invalid value encountered in divide
ret = ret.dtype.type(ret / rcount)
/home/qk/projects/DeepFuseNMF/SpaHDmap/train.py:940: RuntimeWarning: Mean of empty slice.
mean_change = diff_mat1[nonzero_index[0], nonzero_index[1]].mean()
/home/qk/projects/DeepFuseNMF/SpaHDmap/train.py:946: RuntimeWarning: Mean of empty slice.
mean_score_output = smooth_output[nonzero_index_input[0], nonzero_index_input[1]].mean()
Step 5: Train the SpaHDmap model
*** Training the model... ***
[Iter: 200 / 2000], Epoch: 3,Image Loss: 0.021072, Expression Loss: 0.362357, Total Loss: 0.137611,Learning rate: 4.522638e-03
[Iter: 400 / 2000], Epoch: 5,Image Loss: 0.005964, Expression Loss: 0.356573, Total Loss: 0.124086,Learning rate: 3.272888e-03
[Iter: 600 / 2000], Epoch: 7,Image Loss: 0.005560, Expression Loss: 0.358249, Total Loss: 0.127842,Learning rate: 1.728112e-03
[Iter: 800 / 2000], Epoch: 9,Image Loss: 0.004678, Expression Loss: 0.355449, Total Loss: 0.122440,Learning rate: 4.783620e-04
[Iter: 1000 / 2000], Epoch: 12,Image Loss: 0.004473, Expression Loss: 0.356705, Total Loss: 0.122549,Learning rate: 1.000000e-06
[Iter: 1200 / 2000], Epoch: 14,Image Loss: 0.004943, Expression Loss: 0.356362, Total Loss: 0.123397,Learning rate: 3.834837e-04
[Iter: 1400 / 2000], Epoch: 16,Image Loss: 0.004962, Expression Loss: 0.356829, Total Loss: 0.124127,Learning rate: 2.922830e-04
[Iter: 1600 / 2000], Epoch: 18,Image Loss: 0.004440, Expression Loss: 0.356198, Total Loss: 0.122397,Learning rate: 1.599105e-04
[Iter: 1800 / 2000], Epoch: 20,Image Loss: 0.004041, Expression Loss: 0.355137, Total Loss: 0.121526,Learning rate: 4.574560e-05
[Iter: 2000 / 2000], Epoch: 23,Image Loss: 0.003954, Expression Loss: 0.354935, Total Loss: 0.121141,Learning rate: 1.000000e-06
*** Finished training the SpaHDmap model and saved at ../experiments//multi_sections/Results_Rank20//models//trained_model.pth ***
*** Extracting SpaHDmap scores for Palbocilib_A... ***
*** Extracting SpaHDmap scores for Palbocilib_B... ***
*** Extracting SpaHDmap scores for Control_C... ***
*** Extracting SpaHDmap scores for Control_D... ***
*** Visualizing and saving the embeddings of SpaHDmap... ***
After training, NMF, GCN and SpaHDmap scores are available now.
[11]:
pal_A
[11]:
STData object for section: Palbocilib_A
Number of spots: 3073
Number of genes: 5534
Image shape: (3, 7547, 7174)
Scale rate: 2
Spot radius: 32
Image type: HE
Available scores: NMF, GCN, VD, SpaHDmap, SpaHDmap_spot
We can visualize the SpaHDmap score for a specific section and index, section can be a (name of) section or a list of sections (names), if None, all sections will be visualized.
In this case, we visualize the NMF, GCN and SpaHDmap score for the section ‘Palbocilib_A’ and the index 2.
[12]:
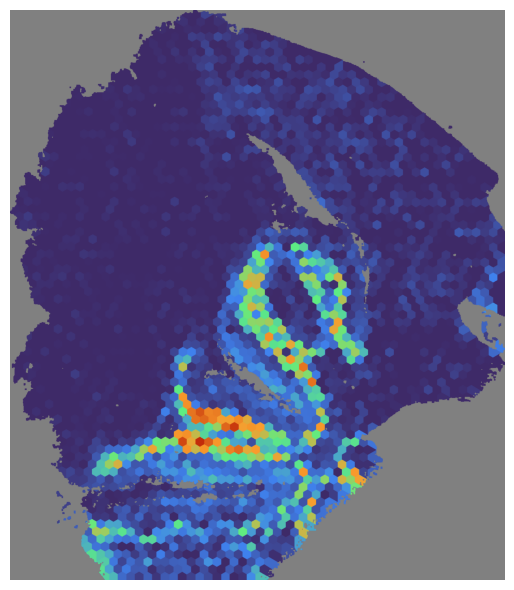
# Visualize the NMF score
mapper.visualize(pal_A, use_score='NMF', index=7)
# mapper.visualize('Palbocilib_A', use_score='NMF', index=2) # visualize pal_A given the name
*** Visualizing and saving the embeddings of NMF... ***
[13]:
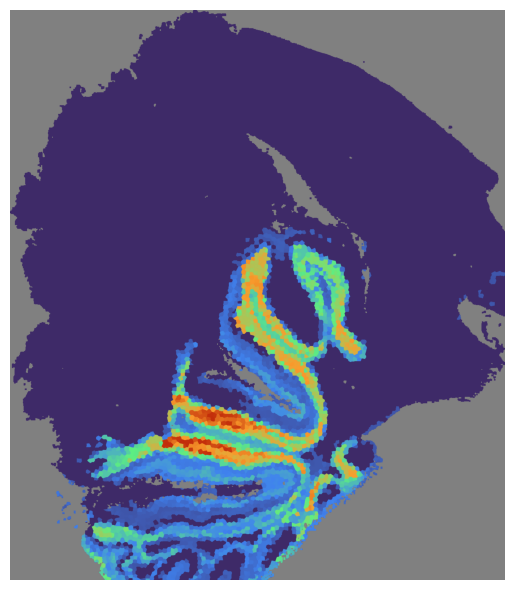
# Visualize the GCN score
mapper.visualize(pal_A, use_score='GCN', index=7)
*** Visualizing and saving the embeddings of GCN... ***
[14]:
# Visualize the SpaHDmap score
mapper.visualize(pal_A, use_score='SpaHDmap', index=7)
*** Visualizing and saving the embeddings of SpaHDmap... ***
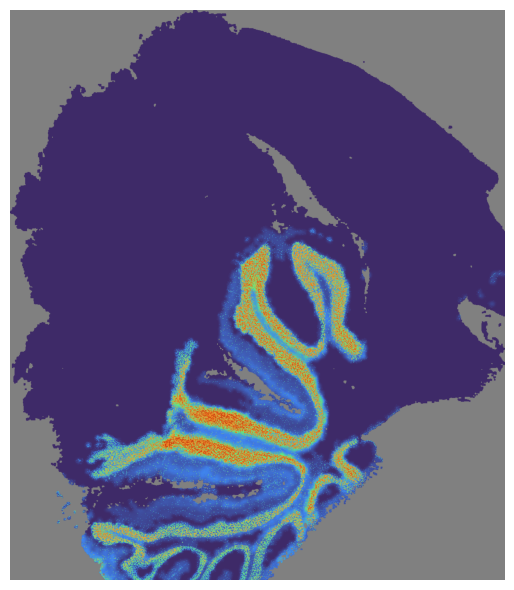
and visualize both section Palbocilib_A and Palbocilib_B.
[15]:
# Visualize multiple sections
mapper.visualize([pal_A, pal_B], use_score='SpaHDmap', index=7)
# mapper.visualize(['Palbocilib_A', 'Palbocilib_B'], use_score='NMF', index=2) # visualize multiple sections given the names
*** Visualizing and saving the embeddings of SpaHDmap... ***
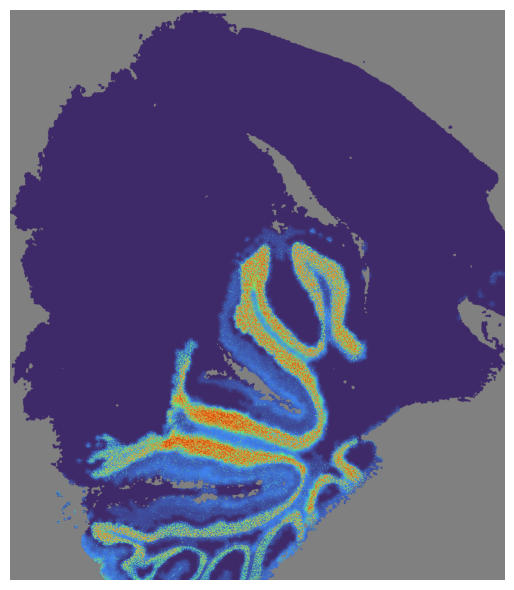
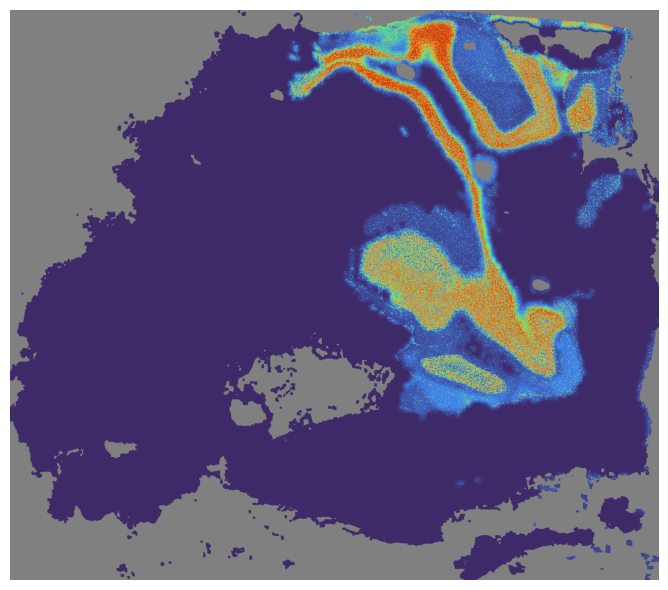
Or visualize SpaHDmap embedding for all section
[16]:
# Visualize all sections for specific index
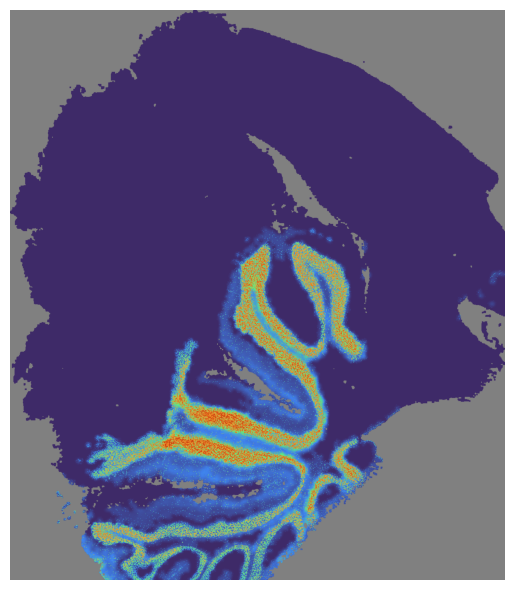
mapper.visualize(use_score='SpaHDmap', index=7)
*** Visualizing and saving the embeddings of SpaHDmap... ***
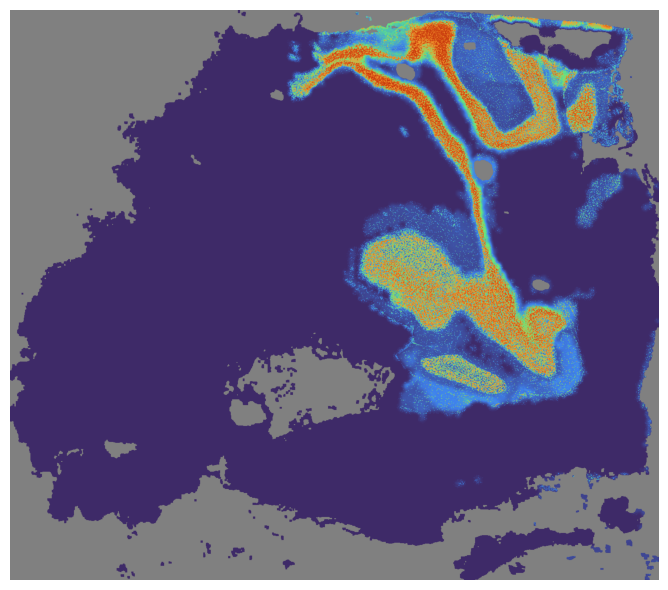


Also, we can visualize without specifying the index, all SpaHDmap scores will be saved in results_path/section_name/SpaHDmap.
[17]:
# Visualize all sections and all embeddings
mapper.visualize(use_score='SpaHDmap')
*** Visualizing and saving the embeddings of SpaHDmap... ***
The final metagene matrix is stored in the metagene attribute of the Mapper object.
[18]:
mapper.metagene.head()
[18]:
| Embedding_1 | Embedding_2 | Embedding_3 | Embedding_4 | Embedding_5 | Embedding_6 | Embedding_7 | Embedding_8 | Embedding_9 | Embedding_10 | Embedding_11 | Embedding_12 | Embedding_13 | Embedding_14 | Embedding_15 | Embedding_16 | Embedding_17 | Embedding_18 | Embedding_19 | Embedding_20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| hg38-A1BG | 0.000000 | 0.283842 | 0.000000 | 0.000000 | 0.129793 | 0.181874 | 0.000000 | 0.000000 | 0.012154 | 0.00000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.091844 | 0.0 | 0.000000 | 0.000000 | 0.000000 |
| hg38-AAAS | 0.000000 | 0.123717 | 0.000000 | 0.000000 | 0.045914 | 0.016794 | 0.000000 | 0.000000 | 0.000000 | 0.00000 | 0.0 | 0.036688 | 0.188972 | 0.0 | 0.004333 | 0.004078 | 0.0 | 0.041981 | 0.013544 | 0.000000 |
| hg38-AAK1 | 0.000551 | 0.081234 | 0.000000 | 0.002743 | 0.003185 | 0.154227 | 0.000000 | 0.000000 | 0.000000 | 0.00000 | 0.0 | 0.008010 | 0.035297 | 0.0 | 0.009859 | 0.010707 | 0.0 | 0.000000 | 0.000000 | 0.000000 |
| hg38-AANAT | 0.002631 | 0.014646 | 0.000000 | 0.000000 | 0.000000 | 0.055124 | 0.000000 | 0.000000 | 0.000000 | 0.00000 | 0.0 | 0.011523 | 0.052625 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.004639 | 0.007837 | 0.000000 |
| hg38-AAR2 | 0.000000 | 0.121178 | 0.007053 | 0.000000 | 0.000000 | 0.084252 | 0.016109 | 0.003555 | 0.000000 | 0.00823 | 0.0 | 0.000000 | 0.134313 | 0.0 | 0.014649 | 0.000000 | 0.0 | 0.000000 | 0.002609 | 0.007407 |
[ ]: